


Stanley Cup-voittajan ennustamisen lisämausteena Digian asiantuntijat tekivät Twitter-datan pohjalta tekstianalyysin, joka kertoo NHL-joukkueisiin liittyvien twiittien sävystä. Lue, miten analyysi toteutettiin.
Syyskuussa ennustimme tekoälyn avulla Stanley Cup-voittajan käyttäen apunamme koneoppimista ja simulaatiota. Koneoppimista hyödyntäen simuloimme koko turnauksen läpi 10000 kertaa, josta laskimme Stanley Cupin voittotodennäköisyydet jokaiselle joukkueelle, ja toistimme prosessin jokaisen ottelukierroksen jälkeen.
Ennusteen lisäksi päätimme tehdä toisenlaisen tarkastelun, jossa pyrimme analysoimaan yleistä keskustelua turnauksesta. Tällaista analyysiä voisi tehdä monilla tavoilla, mutta päästäksemme nopeasti konkreettisiin tuloksiin päätimme hakea Twitteristä twiittejä ja käyttää ns. sävyanalyysiä niiden tutkimiseen.
Sävyanalyysi (englanniksi sentiment analysis) on tekstianalytiikan alue, jossa pyritään määrittämään, onko jokin teksti, tässä tapauksessa yksittäinen twiitti, sävyltään positiivinen, negatiivinen tai mahdollisesti jotain tältä väliltä. Ideana on, että haemme twiittejä, jotka pystymme liittämään tiettyyn joukkueeseen. Tällöin käyttämällä twiittauksen ajankohtaa voidaan kullekin joukkueelle laskea päiväkohtainen keskimääräinen sävy. Tällaisen sävyaikasarjan avulla pystymme esimerkiksi tekemään vertailua, liittyykö joukkueen menestys siihen, minkälaisia joukkueeseen liittyvät twiitit ovat sävyltään.
Tekstianalytiikasta yleisesti
Monilla yrityksillä ja organisaatioilla on hallussaan tekstimuotoista dataa. Tämän lisäksi tekstiä syntyy koko ajan monessa kanavassa kuten sosiaalisessa mediassa. Onkin hyvin mahdollista, että kenelläkään yksittäisellä henkilöllä ei ole hyvää yleiskuvaa jonkin tekstiaineiston sisällöstä.
Luonnollisen kielen käsittely, joka tunnetaan myös lyhenteellä NLP (natural language processing), on tutkimusalue, joka tutkii mm. sitä, kuinka ihmisten tuottamaa tekstiä voidaan ymmärtää ja tuottaa tietokoneen avulla. Viime vuosina alalla on tapahtunut selvää edistystä syvien neuroverkkojen ansiosta, mistä yhtenä kuuluisana esimerkkinä on GPT-3-malli, joka pystyy tuottamaan uskottavan näköistä tekstiä, oli sitten kyse faktasta tai fiktiosta.
Tekstidataa voidaan prosessoida ja analysoida lukuisilla tavoilla, joista tavallisia esimerkkejä ovat esimerkiksi usein esiintyvien sanojen hakeminen ja esittäminen (esim. sanapilven muodossa), tai tekstidokumenttien ryhmittely sen mukaan, mitä sanoja dokumenteista löytyy ja mitkä niistä esiintyvät yhdessä (ns. topic modeling).
Lue myös: Asiakaskokemus kehittyy tekstianalytiikan avulla
Näin data-analyysiprosessi etenee
Data-analyysiprosessi alkaa luonnollisesti datasta, jota tässä tapauksessa haettiin Twitteristä. Twitter tarjoaa rajapinnan (tässä käytimme ilmaista versiota), jonka kautta voi hakea twiittejä. Rajapinnan käyttämiseksi täytyy kysyä Twitteriltä lupaa, mikä tapahtuu osoitteessa developer.twitter.com. Hakemusta tehdessä täytyy antaa erilaisia tietoja liittyen rajapintaa käyttävään tahoon sekä mihin käyttötarkoitukseen rajapintaa oltaisiin käyttämässä. Ilmoitimme, että haluamme hakea urheiluun liittyviä twiittejä, joille soveltaisimme tekstianalytiikan menetelmiä, ja analyysin tuloksia esittäisimme julkisesti. Hakuprosessiin kului muutama päivä, minkä aikana Twitteriltä tuli vielä lisäkysymyksiä.
Kun dataa oli saatavilla, sitä prosessoitiin käyttäen Python-ohjelmointikieltä ja sille saatavilla olevia kirjastoja. Python on tällä hetkellä oivallinen valinta tekstianalytiikkaan, koska suosituimmat neuroverkkokirjastot (kuten Tensorflow ja Pytorch) ja niiden uusimmat tekstianalytiikkasovellukset ovat käytettävissä Pythonilla.
Käytimme twiittien hakemiseen tweepy-kirjastoa, mutta ensiksi piti määrittää, millä perusteella Twitteristä dataa haetaan. Päätimme hankkia twiitit joukkueisiin liittyvien aihetunnisteiden (englanniksi hashtag) perusteella. Joillekin joukkueille, kuten Boston Bruins, sopiva aihetunniste saatiin yksinkertaisesti menemällä heidän Twitter-sivulleen, jossa aihetunniste #NHLBruins on annettu sivun kuvauksessa. Joidenkin joukkueiden kohdalla selasimme heidän virallisilla Twitter-sivuillaan olevia twiittejä, ja valitsimme aihetunnisteet, jotka vaikuttivat liittyvän juuri heihin.
Muut hakuun liittyvät valinnat olivat, että haemme englanninkielisiä twiittejä, jotka eivät ole uudelleentwiittauksia, ja jotka eivät sisällä ns. sensitiivistä sisältöä. Tällöin hakumerkkijonoksi tulee Boston Bruinsin tapauksessa "#NHLBruins lang:en filter:safe -filter:retweets". Muut hakuehtojen määrittämiseen liittyvät ohjeet löytyvät Twitterin omista ohjeista.
Kun dataa on haettu ja varastoitu, siihen voidaan soveltaa NLP-menetelmiä. Sävyanalyysin tekemiseen käytettiin Flair-kirjastoa, jonka avulla pystyy helposti käyttämään valikoimaa edistyneitä neuroverkoille perustuvia NLP-malleja. Tässä tapauksessa käytimme englanninkielistä sävyanalyysiä varten valmiiksi koulutettua DistilBERT-tyyppistä mallia. Kyseinen malli on koulutettu käyttäen IMDb-sivustolta saatuja elokuva-arvosteluita.
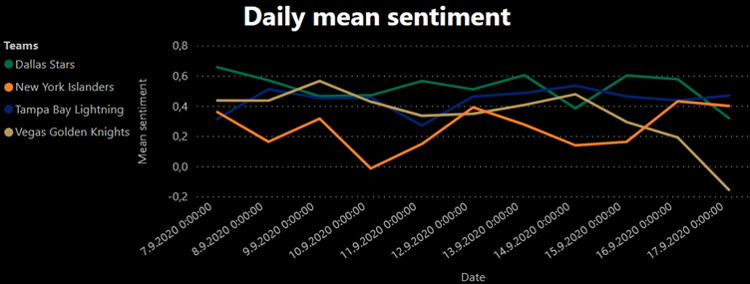
Syöttämällä mallille twiittejä saamme ulostulona sävyä kuvaavan luvun, jonka muutimme luvuksi välille [-1,1], jossa -1 on mahdollisimman negatiivinen ja 1 on mahdollisimman positiivinen. Tämän jälkeen voidaan esimerkiksi laskea joukkuekohtainen päiväkohtainen keskimääräinen sävy, mikä on esitetty seuraavassa kuvassa neljälle joukkueelle aikavälillä 7.9.–17.9.
Sävyanalyysin lisäksi halusimme esittää twiittien sisältöön liittyvää tietoa. Päädyimme hakemaan twiiteistä mainintoja nimetyistä henkilöistä. Tarkoituksena oli löytää mainintoja pelaajista Käytimme tähän spacy-kirjastoa ja siihen löytyvää entiteettitunnistusmallia. Maininnat esitetään sanapilvenä (kuvan data on aikaväliltä 7.9.–17.9.).

Tässä yhtenä ongelmana oli, että malli luokitteli henkilöiksi monia sellaisia asioita, jotka eivät ole henkilöitä. Tämän vuoksi näitä tuloksia vielä siivottiin eri tavoin, minkä jälkeenkin on jäljellä muitakin kuin henkilöihin viittavia sanoja.
Kehittämiskohteita
Saadun ratkaisun avulla pystytään seuraamaan joukkueisiin liittyvän twiittailun sävyä, mutta ratkaisua pystyisi kehittämään ja parantelemaan useilla tavoilla. Yksi olisi datahakuprosessin kehittäminen. Tällä hetkellä haettavien twiittien määrä rajattiin siten, että yhdellä haulla voi tulla kerrallaan enintään 3000 twiittiä, mutta ilmainen hakurajapinta mahdollistaisi vielä suuremman määrän hakemisen. Mahdollisesti vielä tärkeämpi kehityskohde olisi hakuehtojen muuttaminen, sillä emme millään tavalla varmistaneet, että käyttämillämme aihetunnisteilla löydämme kaikista relevanteimman keskustelun. Voi esimerkiksi olla, että on paljon joukkueisiin liittyviä twiittejä, jotka eivät sisällä aihetunnisteita.
Seuraava kehityskohde olisi sävyanalyysi. Tällä hetkellä ratkaisumme pohjautui pääasiassa yhden sävyanalyysimenetelmän antamiin tuloksiin. Ei kuitenkaan ole mitään takeita siitä, kuinka hyvin tulokset pitävän paikkansa. Käyttämämme malli on koulutettu elokuva-arvosteludatalla, mikä voi olla varsin erilaista luonteeltaan verrattuna twiitteihin. Tämän vuoksi olisi hyvä tutkia, kuinka laadukkaita mallin antamat tulokset ovat.
Vielä parempaan tulokseen voitaisiin mahdollisesti päästä, jos kokeiltaisiin useampia erilaisia sävyanalyysimenetelmiä, ja yhdistettäisiin niiden tuloksia. On hyvin tunnettua, että usean erilaisen koneoppimismallin tulosten yhdistäminen voi antaa parempia tuloksia kuin yksittäisen mallin käyttäminen (tällaista ratkaisua käytimme ennustaessamme ottelutuloksia). Vaihtoehtoisia tapoja sävyanalyysin tekemiseen on useita, joista kaupallisista vaihtoehdoista mainittakoon pilvipalvelutarjoajat AWS, Azure ja Google (huomattakoon, että näistä kolmesta vaihtoehdosta ainoastaan Azure tukee suomenkielistä sävyanalyysiä).
Näiden lisäksi itse tuloksista tehtyä analyysiä voisi parantaa ja laajentaa eri tavoin. Analyysi ei ota tällä hetkellä huomioon, että yksi twiitti voi sisältää enemmän kuin yhden hakuehdoissa käytetyistä aihetunnisteista. Tällöin ei ole varmaa, kohdistuuko twiitin sävy vain yhteen vai useampaan joukkueeseen, mikä luonnollisesti hankaloittaa tulosten tulkintaa.
Johtopäätökset
Harjoituksen lopputulemana on, että suhteellisen pienillä resursseilla saatiin aikaan ratkaisu, jolla pystytään seuraamaan joukkueisiin liittyvän twiittailun sävyä. Samanlaisella periaatteella myös yritykset tai organisaatiot voisivat seurata itseensä liittyvän twiittailua.