


Mitä CRM-järjestelmän tuottamalla datalla voitaisiin saada aikaiseksi? Toteutimme asiakasanalytiikan pilotin, jossa tavoitteena oli testata myyntihankkeen onnistumisen todennäköisyyttä CRM-dataan pohjautuen.
Asiakasanalytiikkaa on harjoitettu pitkään, ja luottoriskien arvioinnin ohella se lienee ensimmäisiä tilastollisten menetelmien laajan mittakaavan soveltamiskohteita yritysten liiketoiminnassa. Voisi näin ollen ajatella, että jokainen kivi on jo käännetty tällä saralla.
Kysyntää silti riittää. Yritysten käytössä on enemmän ja monimuotoisempaa dataa pidemmältä ajalta. Menetelmät ja teknologiat ovat kehittyneet ja datatieteen asiantuntijoita on tarjolla. Kaikki tämä mahdollistaa uuden ja monipuolisemman asiakasanalytiikan kehittämisen. Eivätkä kaikki ole tehneet vielä sitä ensimmäistäkään ennustavan asiakasanalytiikan toteutusta.
Asiakasanalytiikkaa hyödynnetään liiketoiminnan päätöksenteossa, kun halutaan saada parempi, dataan pohjautuva ymmärrys asiakkaan käyttäytymisestä. Kysymyksenasettelu on erilainen riippuen siitä mitä asiakaspolun vaihetta ollaan tarkastelemassa.

Päätimme toteuttaa pilotin, jossa tavoitteena oli testata myyntihankkeen onnistumisen todennäköisyyttä. Asiakaspolulle sijoitettuna kysymys on oleellinen kahdessakin kohtaa: alkuvaiheen uusasiakashankinnassa, ja lisämyyntimahdollisuuksien arvioinnissa olemassa oleville, asiakkuuden kehittämisvaiheessa oleville asiakkaille.
Lähestymistapa haluttiin pitää yksinkertaisena: mitä CRM-järjestelmän tuottamalla datalla saadaan aikaiseksi? Digia on merkittävä Microsoft Dynamics CRM -järjestelmätoimittaja. Tämä toi luontevan pohjan lähteä tekemään pilottitoteutusta yhteistyönä asiakkaan kanssa tuotannollisessa ympäristössä. Ennustavan analytiikan pilotoitava käyttötapaus rajattiin B2B-liiketoimintaan.
Kysymyksen asettelu ja data
Liiketoimintakysymys on muokattava sellaiseen muotoon, josta käy yksikäsitteisesti ilmi, miten organisaation toimintaa kuvaavat käsitteet yhdistyvät dataan. On tunnistettava käsitetasolla mallintamisen ”kohde” – ilmiö, jota selitetään tai ennustetaan – ja tunnettava se joukko ”tekijöitä”, jotka potentiaalisesti selittävää ”kohteen” saamia arvoja.
Data scientist tarvitsee tiedon, miten käsitetasoinen tieto mappautuu fyysisesti talletettuun tietoon – millä säännöillä päätellään ”kohteen” arvo? Jos ”kohde” on esimerkiksi ”myyntimahdollisuuden voitto”, mistä tietokannan tauluista ja sarakkeista se löytyy ja liittykö se päättelyyn mahdollisesti muuta logiikkaa?
CRM-järjestelmistä on tunnistettavissa kaksi datakokonaisuutta, joista ennustemallin muuttujat tuotetaan: asiakkaat (”Accounts”) ja myyntimahdollisuudet (”Opportunities”).
Kun ennustava mallinnuksen kohteena on myyntimahdollisuuden voitto/häviö, löytyy kohdemuuttuja datasta yleensä suoraviivaisesti: myyntimahdollisuuksilla voi olla kolme olennaisesti erilaista tilaa (”avoin”, ”voitettu” tai ”hävitty”).
Tyypillisiä CRM-järjestelmästä löytyviä ehdokkaita selittäviksi tekijöiksi ovat
- asiakasyrityksen koko (liikevaihto, henkilöstömäärä)
- asiakasyrityksen toimiala
- myyntimahdollisuuden kesto tähän saakka
- asiakkaalle aiemmin tehdyt aktiviteetit (esim. aiempien myyntimahdollisuuksien lukumäärä, aiemmat onnistuneet/hävityt myynnit)
- onko asiakas kokonaan uusi
- myyntimahdollisuuden vaihe (”myyntihanke avattu”, ”tarjous jätetty”, ...)
- tarjottava palvelu / tuote
- sopimuksen arvo
Ennustemallin opetusaineiston kokoaminen
Asiakasanalytiikan mallintamisessa käytettävä opetusdata kootaan usein seuraavan periaatteen mukaisesti:
- kiinnitetään jokin ajan ”nykyhetki”
- kiinnitetään aikaikkuna, jolta tutkittavaa kohdetta selittävät muuttujat kootaan (”Havaintojakso”, ”Observation window”)
- kiinnitetään aikaikkuna, jolta kootaan kohdemuuttujan arvot (”Kohdejakso”, ”Target window”)
- observation- ja target -aikaikkunoiden välissä voi olla myös ”tyhjä” aikaväli (”Lead window”)

Mallinnuksessa oletetaan, että havaintojakson aikana datariviltä löytyvät tapahtumat selittävät kyseistä havaintojaksoa seuraavan kohdejakson tapahtumia. Esimerkkitapauksessamme ”datarivi” on yhden myyntimahdollisuuden tiedot. ”Nykyhetki” valitaan historiadatan antamien mahdollisuuksien mukaan.
Esimerkkitapauksessamme opetusaineisto koottiin kolmeen eri ”nykyhetkeen” perustuen, jotta opetusaineistoa saatiin riittävästi. Yhtenä ”nykyhetkenä” oli 31.3.2019. Opetusaineisto muotoutuu tähän ajankohtaan perustuen siten, että
- otetaan kaikki kyseisellä päivällä 31.3.2019 olevat avoimet myyntimahdollisuudet
- katsotaan datasta mitä näille myyntimahdollisuuksille on tapahtunut kohdejakson (tässä tapauksessa seuraavat 3 kk) aikana: onko voitettu, hävitty vai edelleen avoin
- haetaan myyntimahdollisuus-datasta mallinnuksessa tarvittavat muuttujat nykyhetkeä edeltävältä ajalta
- esimerkkinä mallin selittävästä muuttujasta ylempänä mainittu myyntimahdollisuuden kesto; jos myyntimahdollisuus on avattu (kirjattu järjestelmään) esim. 15.1.2019, on myyntimahdollisuuden kesto tälle datariville 31.3.2019 – 15.1.2019 = 74 päivää.
Edellä kuvatulla tavalla toimien muotoutuu ennustemallin opetusaineisto, jossa on myyntimahdollisuuksien tarvittavat taustatiedot sekä tieto siitä onko kyseinen myyntimahdollisuus voitettu vai ei-voitettu tulevan 3 kk jakson aikana.
Mallinnusvaihe
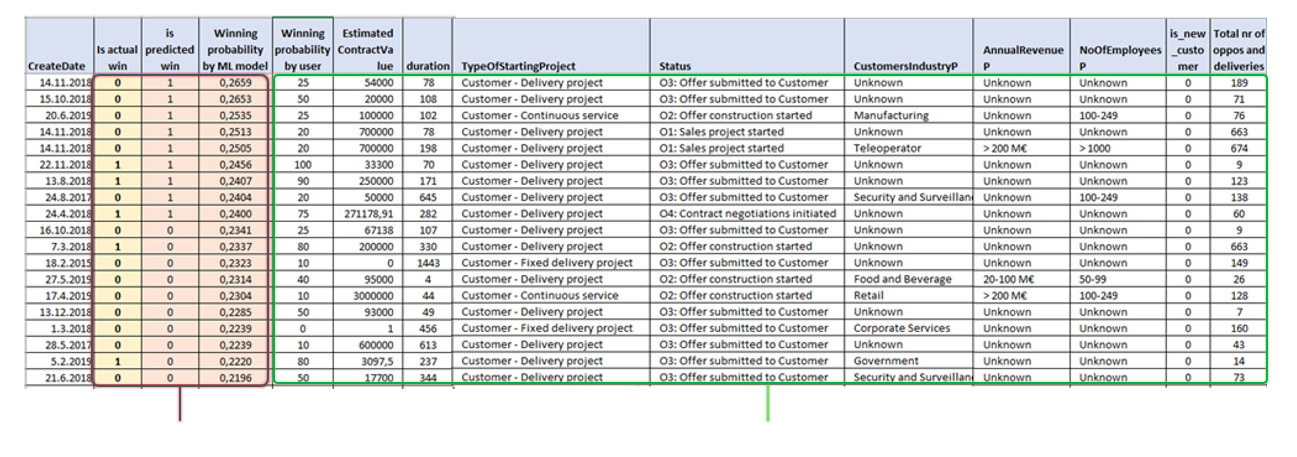
Ennustemallia opetetaan aineistolla, jonka luomisen periaatteet kuvattiin edellisessä luvussa. Lopputuloksena on alla olevan kuvan mukainen tietonäkymä, jossa myyntimahdollisuudet (”Oppo”) ovat riveillä. Selittävät muuttujat valitulta jaksolta sekä valittu jaksoa seuraava lopputulema (”voitto” / ”ei-voitto”) ovat taulun sarakkeina.

Ennen varsinaista mallintamista selittäville muuttujille on usein tarpeen tehdä esikäsittelyä, jotta varsinainen mallialgoritmin opettaminen onnistuu parhaalla mahdollisella tavalla. Esikäsittelyvaiheessa on syytä vähintään läpikäydä seuraavat asiat:
Kannanotto ja tyhjiin ja selvästi poikkeaviin arvoihin
Halutaanko selittävissä muuttujissa olevat tyhjät arvot korvata jollakin sopivalla tavalla esim. nollilla, vai halutaanko tyhjiä tai outlier-arvoja sisältävät havainnot jättää opetusaineistosta pois kokonaan.
Vinosti jakautuneiden numeeristen muuttujien käsittely ja tasoittaminen
Esimerkkitapauksessa myyntimahdollisuuden kesto on esimerkki selittävästä muuttujasta, joka on voimakkaasti ”vasemmalle vino”: suurin osa muuttujan arvoista on ”pieniä”, mutta löytyy kauan auki olleita myyntimahdollisuuksia, jotka tekevät keston jakaumaan ”pitkän hännän”.
Kategoristen (”ei-numeeristen”) muuttujien käsittely
Kategoriset muuttujat uudelleenkoodataan numeerisiksi, ja harvoin esiintyviä kategorioita voi olla aiheellista yhdistää: esimerkiksi asiakasyrityksen toimialat, joille on ollut vain yksittäisiä myyntimahdollisuuksia, voi olla perusteltua niputtaa yhden ”Other business”-luokan alle.
Muuttujien normalisointi
Selittävinä tekijöinä olevien numeeristen muuttujien arvoalueet voivat poiketa toisistaan huomattavasti: sopimuksen arvo voi vaihdella vaikkapa sadasta eurosta miljoonaan euroon, mutta esimerkiksi ”Onko asiakas uusi” saa arvoja 0 ta 1. Eri skaaloissa olevat muuttujat on saatettava matemaattisin muunnoksin ennen mallialgoritmin sovittamista samalle lukualueelle.
Varsinaisessa mallin opettamisessa testataan useampaa algoritmia, joista yksi valitaan tuotantokäyttöön. Yllä tuotettu opetusaineisto jaetaan kahteen osaan: ”Train”-data, jolla algoritmi viritetään, ja ”Test”-data, jolla algoritmin tuottaman mallin tarkkuus validoidaan.
Valitsemisen perusteena on usein jokin tilastollinen tunnusluku, joka mittaa mallin antaman ja ”Test”-aineistossa olevan vastaavan toteuman välistä yhteneväisyyttä. Joskus valintaperusteena voi olla myös vaatimus mallin tulkittavuudelle: halutaan käyttää vaikkapa regressiomallia, koska regressiomallissa selittävien muuttujien vaikutus kohdemuuttujaan on helposti tulkittava suoraan mallin parametreista.
Yllä kuvatut mallinnukseen liittyvät muuttujien esiprosessointi-, opetus- ja validointivaiheet ovat geneerisiä ja toistuvat samankaltaisina riippumatta siitä minkä tyyppinen liiketoimintakysymys on ratkaistavana. Näin ollen, kun olet kerran toteuttanut yllä kuvatun kaltaisen koneoppimiseen pohjautuvan myyntimahdollisuuksien voittamisen ennustemalliprosessin, olet tullut samalla luoneeksi hyvän pohjan tehdä ennustemalliin vaikkapa asiakaspoistumaennustemallille.
Myyntimahdollisuuden voittotodennäköisyysmallin tuloksista
Teimme mallinnuksen kahdella eri CRM-data -aineistolla, toinen Digian asiakkaan, toinen Digian omasta CRM-järjestelmästä. Kumpikin CRM-järjestelmä pohjautuu Microsoft Dynamics 365 -tuotteeseen, joten käytettävissä oleva lähtödatat olivat rakenteeltaan lähes samat. Käytössä oli siis kutakuinkin samat ehdokkaat myynnin onnistumista selittäviksi muuttujiksi.
Näiden kahden valitun tapauksen toimintaympäristöt ja liiketoiminnat poikkeavat toisistaan: Digia yrityksenä edustaa tietotekniikan palveluliiketoimintaa, ja toinen kokeilussa ollut yhtiö energia-alan asiantuntija-, tukku- ja vähittäismyyntiliiketoimintaa. Myynnin ja asiakkuudenhallinnan prosesseissa sekä CRM-järjestelmän käytössä oli kuitenkin nähtävissä yhtäläisyyksiä.
Myös myyntimahdollisuuksien voittotodennäköisyysmallin lopputulos näiden kahden esimerkkiyhtiön osalta näytti samankaltaiselta: ennustemallin merkittävimmiksi selittäviksi tekijöiksi osoittautuivat kummankin yrityksen kohdalla samat muuttujat, hyvin lähellä toisiaan olevilla painoarvoilla.
Ennustemallien tarkkuudet olivat verrattain hyviä. Testiaineistoissa noin 85 % mallin antamista ennusteista osui oikein, ts. se mikä ennustettiin voitoksi (tai tappioksi), oli voitto (tappio) myös oikeasti.
Mallin käyttö
Voittotodennäköisyysmallinnuksen keskeisin lopputulos on opetusaineistolla viritetty koneoppimisalgoritmi, joka tuottaa ennusteita avoimille myyntimahdollisuuksille jatkuvana prosessina, esimerkiksi kerran viikossa kaikille avoimille myyntimahdollisuuksille.
Todennäköisyyksien ajastettua laskentaa varten tarvitaan lähtötietojen yhdistely- ja muokkausrutiinit, jotka muotoilevat ennustemallille syöttötietona menevän datan oikean muotoiseksi. Yleensä tässä kohti voidaan hyödyntää mallinnusvaiheessa jo kerran tehtyjä datan muokkausrutiineja.
Lopputulokset voidaan tallentaa taulumuodossa, joka pitää sisällään (viikottaiset, kuukausittaiset) mallin antamat kyseisen ajanhetken avointen myyntioppojen voittotodennäköisyydet, sekä tällöin voimassa olleet selittävien muuttujien arvot.
Data
Laadukas ja riittävän kattava data on edellytyksenä hyvälle ennustemallille, eikä myyntimahdollisuuden voiton ennustemalli tee tässä poikkeusta. Verrattuna vaikkapa monimutkaisista teollisuuden tuotantoprosesseista dataa kerääviin IoT-järjestelmiin CRM-järjestelmät ovat kompakteja: datapisteitä ei ole paljon eikä ehdokkaita selittäviksi tekijöiksi ole massiivisia määriä. Tästä yksinkertaisuudesta huolimatta datan laadullinen tarkastelu osoitti, että vaikka ennustetarkkuus oli verrattain hyvä, parempaankin voitaisiin päästä. Jo yllä oleva dataesimerkki osoittaa muutaman laadullisen puutteen:
- Oletettu sopimuksen arvo sisältää joskus kyseenalaista tai ei-ajantasaista tietoa – nollan ja yhden euron suuruisia sopimuksen arvoja esimerkkikuvassa. Voi olla, että myyntimahdollisuuden kirjaushetkellä sopimuksen arvoa ei tiedetä, ja CRM-järjestelmä pakottaa syöttämään sopimuksen arvoksi ”jotakin”, jota ei muisteta käydä päivittämässä sen jälkeen, kun täsmällisempi tieto on saatu.
- Asiakasyrityksen taustatietoja on syötettynä vaihtelevasti – niitä ei ehkä tiedetä, mutta syynä voi olla myös se, että koska toimiala, liikevaihtoluokka, jne. eivät ole pakollisia tietoja, ne jätetään tyhjäksi (”Unknown”), jolloin asiakasyritykseen sisältyvä informaatio jää hyödyntämättä.
Myyntihankkeen status ja kesto ovat mallissa tärkeitä selittäjiä, joten myyntimahdollisuuden syntymispäivä ja muutokset hankkeen statuksessa on tärkeitä kirjata oikein ja sille ajankohdalle, jona ne ovat oikeasti tapahtuneet.
Tarkoituksena ei ole syyllistää CRM-järjestelmien käyttäjiä: on tilanteita, jossa täsmällistä tietoa ei vielä ole saatavilla, ja kirjaus on tehtävä vaillinaisin tiedoin. Lisäksi manuaalisessa työskentelyssä on inhimillistä, että syöttövirheitä syntyy. Kohti oikeellisempaa ja ajantasaisempaa dataa voidaan edetä pienin askelin vaikkapa ohjeistamalla ja yhdenmukaistamalla järjestelmien käyttöä. Kun tiedon laadun parantuessa huomataan samalla ennustemallin parantunut tarkkuus ja sen tuoma hyöty, kannuste taustajärjestelmien fokusoidummalle käytölle syntyy kuin itsestään.
Seuraavat askeleet
Analytiikkaprojektit pohjautuvat luontevasti liiketoiminnasta tunnistetun käyttötapauksen ympärille. Liiketoiminnalla on jokin selkeästi rajattu ”ongelma”, johon data-analytiikalla haetaan ”ratkaisu”. Nyt toteutettu käyttötapaus syntyi tarpeesta saada parempi, ei-subjektiivinen, dataan pohjautuva käsitys siitä mikä on myyntimahdollisuuksien onnistumisen todennäköisyys, ja laajemmin mikä on kaikkien avoimien myyntimahdollisuuksien keskinäinen paremmuusjärjestys – mitkä avoimet caset ovat tässä ja nyt hot ja mitkä not.
Seuraava mallinnustoteutus saman aihepiirin ympärillä on yleensä helpompi. Asiakas- ja myyntidatan keruuseen liittyvät datanpoimintarutiinit on jo kertaalleen luotu, ja niitä voidaan yleensä käyttää pienin muokkauksin seuraavan asiakasanalytiikka-käyttötapauksen toteuttamiseen. Uuden käyttötapauksen toteutuksessa voidaan kokeilla edellisessä toteutuksessa tuotettuja ehdokkaita selittäviksi tekijöiksi. Mallin muuttujien esiprosessoinnissa, mallialgoritmien opettamisessa ja validoinnissa voidaan hyödyntää ensimmäisen toteutuksen tuotoksia.
Esimerkkitapauksessamme seuraavia soveltamiskohteita voisivat olla:
- Asiakkuuden hiipumisen analysointi ja ennustaminen: mitkä tekijät johtavat siihen, että yrityksen palveluiden käyttö vähenee tai lakkaa kokonaan? Keillä on suurin poistumariski seuraavien kuukausien aikana?
- Myydystä palvelusta generoituvan liikevaihdon ennustaminen: kun myyntimahdollisuus voitetaan, kuinka paljon tästä tehty palvelusopimus oikeasti tuottaa liikevaihtoa? Kuinka hyvin myyntivaiheessa annettu subjektiivinen näkemys sopimuksen arvosta pitää paikkansa ja voidaanko ennustetta parantaa koneoppimisen menetelmin?