

Jääkiekko on nopeatempoinen ja dynaaminen urheilulaji, jossa monet tekijät vaikuttavat lopputulokseen, mikä tekee ennustamisesta haastavaa. Koneoppimistekniikat tarjoavat tavan parantaa ennustetarkkuutta. Tässä blogissa tutkin, kuinka satunnaismetsä-malleja voidaan valjastaa ennustamaan jääkiekon voittajia ja samalla tehostamaan päätöksentekoa niin urheilussa kuin liiketoiminnassakin.
SM-liigan pelien seuraaminen ja voittajien spekulointi ovat ilo, mutta viime kaudella veimme harrastuksen askeleen pitemmälle: päätimme kokeilla, voimmeko hyödyntää Liiga-dataa ja rakentaa mallin, jolla voimme ennustaa Liigan voittajan niin runkosarjan kuin loppuotteluidenkin kohdalla. Mallin onnistumisprosentti 76 yllätti tekijänsäkin. Onhan sitä kilvoittelua siis jatkettava tälläkin kaudella.
Lisäjännitystä tuo, kun julkaisemme ennusteen ja seuraamme sen paikkansa pitävyyttä julkisella areenalla, kuten viime kaudellakin.
Tässä blogitekstissä keskityn ennusteen tekniseen toteutukseen, kerron työprosessin etenemisestä ja avaan tehtyjä valintoja. Jos olet kiinnostunut lopputuloksesta, eli itse ennusteesta, siirry suoraan tänne.
Toteutustavaksi valikoitui satunnaismetsä-malli
Jääkiekko-ottelun lopputuloksen ennustamiseen liittyy lukuisten muuttujien analysointia: joukkuetilastot, pelaajien suoritukset, aikaisemmat ottelut ja monet muut tekijät vaikuttavat arviointiin. Tämä monimutkaisuus johtuu urheilun dynaamisesta luonteesta, jossa yksittäisen pelaajan suoritus tai jokin yllättävä tapahtuma voi muuttaa pelin tulosta.
Aloitimme siis käsillä olevan ongelman määrittelyllä. Koska meillä oli käytössä suuri määrä peleihin liittyviä ominaisuuksia ja määritelty ennustamisen kohde, oli kyseessä ohjatun koneoppimisen ongelma. Perinteisillä tilastollisilla malleilla on usein vaikeuksia saada kiinni näistä ominaisuuksien vivahteista, mutta satunnaismetsä-mallit ovat erinomaisia tällaisten monitahoisten tietojen käsittelyssä. Ja niinpä päädyimme käyttämään ennusteessamme, useiden muiden vaihtoehtojen harkinnan jälkeen, satunnaismetsä-mallia (ns. random forest).
Mitä ovat satunnaismetsä-mallit?
Ennen kuin sukellamme satunnaismetsä-mallien sovelluksiin jääkiekon ennustamisessa, tarkastelemme lyhyesti, mitä satunnaismetsä-mallit ovat. Satunnaismetsä on koneoppimismalli, tarkemmin sanottuna ensembleoppimismalli eli koneoppimistekniikka, jossa useita malleja yhdistetään kokonaissuorituskyvyn parantamiseksi. Luokitteluongelmassa se yhdistää useita päätöspuita ja tekee lopullisen päätöksen sen mukaan, minkälaiseen tulokseen enemmistö päätöspuista tulee.
Kutakin päätöspuuta harjoitetaan datan satunnaisen osajoukon pohjalta ja lopullinen ennuste on kaikkien puiden ennusteiden yhdistelmä. Tämä kokonaisuus parantaa ennustetarkkuutta ja vähentää ylisovitusta ja varianssia (lue lisää näistä koneoppimisennusteiden tyypillisistä haasteista täällä). Lisäksi satunnaismetsät eivät ole herkkiä heikolle datalle, kuten puuttuville datapisteille, ja kykenevät tekemään arvion puuttuvan datan sisällöstä sekä tasapainottamaan epätasapainoisessa datassa olevia virheitä. Niiden heikkouksia toisaalta ovat monimutkaisuus ja suuri laskentatehon tarve.
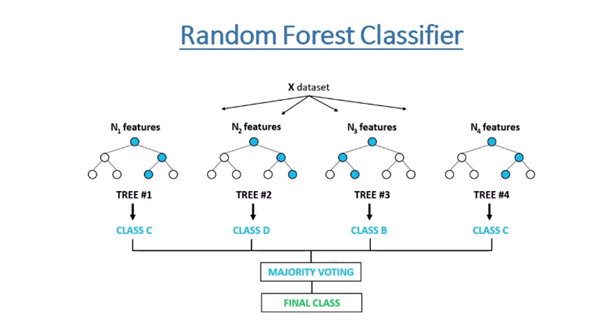
Kuvan lähde: freecodecamp.org
Data on kaiken perusta, ja sen saanti oli ratkaiseva vaihe
Minkä tahansa koneoppimisprojektin perustana on data. Tätä ennustusmallia varten kerättiin ottelutuloksia kaudelta 2023–2024 (ja viime vuonna, kun malli alun perin julkaistiin, tietenkin edelliseltä kaudelta). Lisäksi malli päivittyy jatkuvasti uusilla peleillä kauden 2024–2025 edetessä ja samalla tiputtaa vanhimpia pelejä pois ennusteesta. Tämän lisäksi keräsimme pelaajastatistiikkaa, muun muassa pelaajien tilastotietoja ja historiallisia suoritusmittareita.
Dataa keräsimme SM-liigan APIn kautta uudistuksen alla olevasta tilasto- ja tulospalvelusta, josta dataa oli runsaasti tarjolla ja data oli yleisesti hyvänlaatuista – eikä ihme, osana tilasto- ja tulospalvelun uudistusta Liigan dataa on tarkistettu ja tarkennettu. Tämä datan rikkaus mahdollisti projektissamme monipuolisen lähestymistavan pelien lopputulosten ennustamiseen. Jääkiekon ennustamisessa ominaisuuksien (feature) valinta on ratkaisevan tärkeää mahdollisimman tarkan tuloksen saamiseksi.
Tässä on joitain olennaisia ominaisuuksia, joita voidaan ottaa ennustuksen mallintamisessa huomioon ja, joista osaa olemme käyttäneet ennustuksessamme (avaan myöhemmin tekstissä, miten lopulliset valinnat tehtiin):
Joukkueen tilastot:
- Tehdyt ja päästetyt maalit
- Ylivoima- ja alivoimapelien tehokkuus
- Aloitusten voittoprosentit
- Laukaukset maalia kohden
Pelaajien suorituskykymittarit:
- Yksittäisten pelaajien tilastot (esim. maalit, pisteet, syöttöpisteet)
- Pelaajien luokitukset, eli mikä vaikutus lopputulokseen on puolustajien, maalivahtien ja hyökkääjien suorituksella
- Aika jäällä
Pelin konteksti:
- Pelipaikka (kotona tai vieraissa)
- Viimeaikaiset pelit ja voittoputket
- Vastakkain pelattujen otteluiden lopputulokset eri joukkuepareilla (kausi 2022-2023 + tämä kausi)
Loukkaantumiset ja kokoonpanot:
- Pelaajavammat, pelikiellot
- Aloituskokoonpanot
Sitten siivoamaan! Suuresta datamassasta valikoitiin olennaisimmat muuttujat
Tiedon kokoamisen jälkeen yhdistimme pelaajastatistiikkaa otteluiden tuloksiin joukkue- ja pelipaikkakohtaisesti. Tämä integraatio loi kattavan datajoukon, joka heijasteli sekä yksittäisiä suorituksia että joukkuetilanteita ja tarjosi perusteellisen näkökulman ennustemallin mahdollisiin lopputuloksiin.
Tehokkaalle mallinnukselle keskeistä on selkeys. Alussa datassamme oli erittäin suuri määrä ominaisuuksia, ja tutkimme perusteellisesti niiden olennaisuutta ja vaikutusta malliimme. Huomasimme osalla ominaisuuksista olevan vain vähäinen merkitys siihen, kuinka hyvin malli ennusti lopputuloksia. Selkeyttääksemme mallia poistimme lopullisesta datasta nämä ominaisuudet. Valikoimme mukaan vain ne ominaisuudet, joiden vaikutus oli 99 % kokonaisuudesta.
Datajoukko läpäisi siis tiukan siivousprosessin, jossa ennustustehtävään liittymättömät piirteet poistettiin. Lisäksi numeerisista attribuuteista poikkeavat piirteet, jotka saattoivat mahdollisesti vääristää ennustetuloksia tai tuoda turhaa häiriötä, suljettiin pois. Nämä sisälsivät sellaisia ominaisuuksia kuin yleisömäärät otteluissa ja pelipaidan väri. Satunnaismetsä-mallit ovat kestäviä poikkeaville ja meluisille ominaisuuksille, joita datasta voi löytyä ja jotka ovat yleisiä urheiluanalytiikassa. Ne myös voivat erottaa hetkellisen poikkeaman normin ja merkitsevän trendin väliltä ja tarjoavat ominaisuuksien välille pisteytettävyyttä, joiden avulla analyytikot ja valmentajat voivat tunnistaa, millä muuttujilla on merkittävin vaikutus pelien tuloksiin. Tämä voi auttaa strategiaa ja (tiedostettua) päätöksentekoa tehtäessä.
Koulutus käyntiin: ensimmäinen versio
Puhtaalla ja jäsennellyllä datalla koulutimme ensimmäisen mallin käyttäen satunnaismetsä-algoritmia. Tarkastelimme saaduista tuloksista mallin tarkkuutta ja myös sitä, ovatko tulokset yhtään linjassa reaalimaailman kanssa. Tässä hyödynsimme sellaisia menetelmiä kuin F1-score, grid search ja ristiinvalidointi, joiden avaaminen jää myöhempiin teksteihin – sekä omaa Liigan tuntemustamme. Lisäksi teimme hyperparametrien optimointia mallin parhaan suorituskyvyn hienosäätämiseksi. Aggregoimalla ennusteita useista päätöspuista satunnaismetsä-mallit jo itsessään vähentävät ylisovituksen riskiä ja parantavat ennusteiden vakautta, joihin liittyviä kysymyksiä olimme pohtineet projektimme alkuvaiheilta asti.
Testausta, optimointia ja jatkuvaa parantamista
Ennen mallin käyttöönottoa todellisiin ennusteisiin testasimme sitä playoff-datan avulla vuodelta 2022–2023. Tämä vaihe oli ratkaiseva ymmärtääksemme mallin soveltuvuutta todelliseen maailmaan. Tämän vaiheen merkittävä osa oli selvittää, kuinka monen aikaisemman ottelun otos oli optimaalinen ennusteille ja yhä tunnistaa ominaisuudet, joilla oli vähäinen vaikutus mallin ennusteisiin. Tässä vaiheessa totesimme, ettei mallin ennustetarkkuus parantunut, vaikka aiempia pelejä oli mukana enemmän kuin yhdeltä kaudelta, ja kauden 2021–2022 pelit pudotettiin pois.
Testauksen jälkeen koulutimme mallia uudelleen, ottaen huomioon edellä saadut oivallukset. Ennusteeseen vain vähäisesti vaikuttavat piirteet jätettiin mallista pois tehokkuuden parantamiseksi. Lisäksi tälle kaudelle vaihdettiin vuoden 2023–2024 otteluiden data koulutusdatasettiin päivittämään malli uudemmilla peleillä, ja joukkueisiin päivitettiin kauden 2024–2025 pelaajat. Tämän uudelleenkoulutuksen jälkeen mallilla myös tehtiin ensimmäinen ennuste Liigan voittajasta.
Kuten kaikki teknologia, myös koneoppimismallit vaativat ajoittaista päivittämistä toimiakseen halutusti ja jotta ennusteet pysyvät ajankohtaisina. Kauden edetessä mallia on päivitetty ja päivitetään edelleen tuoreilla tulostiedoilla, joilla varmistetaan, että mallin ennusteet heijastelevat liigapelien uusimpia kehityksiä.
Tekoäly on tulevaisuudessa valmentajien ja analyytikkojen työkalu?
Listasin tässä prosessin vaiheet erityisesti tämän ennusteen toteuttamisen näkökulmasta, mutta samaa metodologiaa voidaan hyödyntää mihin tahansa ennustemallinnustehtävään urheilu- ja liiketoiminta-analytiikassa.
Jääkiekkomaailmassa voittajien ennustaminen on monimutkainen tehtävä lajin dynaamisen luonteen ja lukuisten vaikuttavien tekijöiden vuoksi. Satunnaismetsämallit ovatkin nousseet tehokkaaksi työkaluksi tähän haasteeseen vastaamisessa, ja ne tarjoavat arvokkaan lisäresurssin niin urheiluanalyytikoille, valmentajille kuin harrastajillekin.
Urheiluanalytiikan kehittyessä satunnaismetsä-malleilla, muiden koneoppimistekniikoiden ohella, on todennäköisesti yhä tärkeämpi rooli jääkiekon otteluiden ennustamisessa ja strategian kehittämisessä. Niiden avulla tiimit ja analyytikot voivat saada kilpailuetua ja kykenevät tekemään tietoisempia päätöksiä sekä jäällä että sen ulkopuolella.
Katso kuka voittaa
Pääset tutustumaan tekoälyn tekemään Liigan voittajaennusteeseen täällä >